
Deep Dive: Filecoin Solana Use Cases
A deep dive into IPFS, Filecoin and how to leverage its power in the Solana Ecosystem.

In this article, I will be explaining
What is IPFS
What is Filecoin
Filecoin use-cases in Solana Ecosystem
I will be explaining all these concepts in a simple language so that everyone can understand, although I will go in-depth into these concepts. If you are familiar with any of the concept above, feel free to skip it.
1. What is IPFS
The InterPlanetary File System (IPFS) is a protocol and peer-to-peer network for storing and sharing data in a distributed file system[Source: Wikipedia]. Lets break it down:-
A protocol is a standard set of rules which are used for formatting and processing data. A protocol is a description on how data should be packaged(description == Standard set of rules). Computers are able to communicate with each other using protocols. Best example of a protocol is http. http protocol is widely used by webpages. To launch any website on the internet, we use the standard http protocol. Our computers contact and fetch the webpage present in server through the http protocol.
Now, IPFS is a peer-to-peer network. If you are familiar with blockchain, then you might know what is peer-to-peer(P2P). Peers are non other than individuals and peer-to-peer means individuals interacting directly with each other. A P2P network is a group of computers which are connected together. By achieving this, computers can share data among themselves.

We will be comparing IPFS with https because IPFS’s main objective is to replace https protocol. Sounds difficult to achieve but lets find out
How does IPFS work?
As said earlier, IPFS does two things: Storing data and making data accessible for the person who requested it. IPFS uses content addressing rather than location addressing for storing data.
Webpages are stored in a server and every server has an IP Address (location). You fetch data from server by sending a http request which contains the server ip address.
CID
IPFS uses a concept called content addressing. From a low level perspective, a CID is a cryptographic hash which is used to label the data. When you pass data to a hashing algorithm for example SHA256, you get a unique string containing 256 characters. This string(or hash) is fixed to that data. Meaning only the data you passed can produce that string, even if you change a letter or a bit in that data, it can produce a complete new string which cannot be compared with the original string. There are so many hashing algorithms and IPFS uses SHA256 as a default.
Anatomy of CID
We will be understanding the anatomy of CID.

A CID consists of Codec and a Multihash. Codec is used for encoding and decoding data. A Multihash consists of 3 things: type, length and value. Value is the original hash of data. IPFS uses SHA2–256 hashing algorithm as default but we can use other algorithms as well. This is preceded by length of hash. And then again it’s preceded by the type of hash used(used here is SHA2–256)
Core Mechanism of IPFS
As we know that for a blob of data, we have a unique label(referred as a digital fingerprint). A label just points to the data. Now where is the data stored? Well, data is stored on computer present in the network. Let me explain it clearly.
First, you can add your computer to the IPFS network by simply installing and running the IPFS application. Now this computer is referred as peer in network. Suppose Person A has added his computer to the network. Now he has a file called weatherdata in his computer. What he does is that he imports the file in the IPFS application. When he does that, a CID for the weatherdata file is generated.

From the picture, you can see that after you import file, you get a CID. The string below(QmUZJ….) is the CID for the file. Person B can download the weatherdata.txt file from Person A by searching with the file CID. When Person B downloads the file, it gets stored in cache as well. So, a when a Person C wants to download the file, he can get it from both A and B.
Behind the scenes, IPFS protocol uses DHT(Distributed Hash Table). DHT is a simple key-value table. Here key is the peer id (Every computer has a unique id called peer id). Value here is the CID of file. So, every peer has this DHT table. So, here the Person B enters the CID in application and then IPFS looks up for peers containing this CID with the help of the DHT table.
IPFS protocol represents a file in form of Merkle Tree, specifically a Merkle DAG. Briefly, if there is a large file, this file is chunked into pieces and each piece is given a hash. All these hashes are then computed to form the root hash which is the CID. This is an in-depth concept and I will provide a reference link at the end of article so please check it.
Now you have a basic idea on IPFS, lets get to know why should we use it and then lets understand whether IPFS is feasible right now or not.
IPFS use cases and feasibility
After knowing how IPFS work, you will find that it is similar to how a torrent works. You can fetch a file from two or more peers in chunks.
Advantages
According to statistics, a website can live only 100 days. Whereas a file in IPFs can live forever theoretically as even if you delete it from your system, it can live on other systems in the network.
File sharing is simple. Example, If a video is watched by 10 people in same room, with http protocol, all the 10 people will hit the same server. This increases the load on server which is not good. Suppose if you use IPFS, you can download it at a faster rate as so many peers have it.
Suppose you want to download a movie, there are lot of links available on the internet but there is no way to check if all those links actually has the movie. There is a high possibility that the movie link may point to another file. This can be avoided in IPFS with help of CID. Because a movie(file) will have only one unique CID and all peers with this CID only provide the movie you want. So, you will always download the desired file with use of CID
IPFS enables the power of decentralization because there is no such thing as a central server.
Drawbacks of IPFS
Inorder to access data from a node in the network, the node should be running. Meaning, if a computer in the network is turned off, you cant access any data from it. You should remember that nodes in the network are generally operated by people. Whereas, a http website is hosted in a server residing in a datacenter of maybe GCP, AWS, Azure etc. These servers keeps on running until you pay.
So, inorder to make IPFS as successful as http, you need large number of peers across the world which currently is not the case. There are very few people who know about IPFS.
Although there is a dns system and an ipfs-search site, it is no way near to Google and other search engines. You can find your desired data in ipfs-search. Also very few people use dns for their CID. Without DNS, knowing a CID is basically useless as you can say what data a CID possess.
By this, you get an idea that IPFS is no way near to replace https.
But, most important thing is you need to understand that IPFS is a protocol. This protocol acts as a backbone to the decentralized storage system. Filecoin uses IPFS to provide storage to the applications. Next, we will discuss how Filecoin solves each and every drawback of IPFS to become a pioneer in providing storage to Web3 ecosystem.
2. What is Filecoin?

Filecoin is a decentralized storage on which anyone can store and retrieve data.
First, lets get to know about centralized and decentralized storage. Some of centralized storage providers are AWS, GCP etc. These companies have large datacenters and offer storage as a service. You pay for using a certain amount of storage for a period of time.
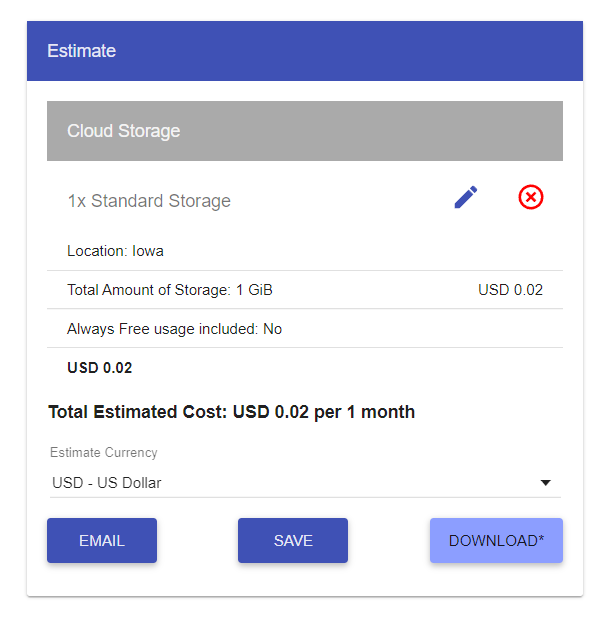
From the above image, you see that in GCP for 1 GB of data, you pay around 0.02 USD per month. Now this is an example of storage as a service and it is referred as a centralized storage as this will be maintained by one central entity, here its google.
Whereas, a decentralized storage network also provides storage as a service but there is no central entity. Anybody who wants to provide storage can join the network. Like any other big organizations, even filecoin network has big datacenters which or operated by small group of people or organizations.
Now you may have the doubt like why do we need to chose a decentralized storage rather than a centralized storage? There are many factors but ultimately factor that people care is the cost. At this moment, getting 1 GB of data for 30 days costs $0.0000002 USD which is 1,00,000 times cheaper compared with the google storage offering. Click Here to check the stats of filecoin storage and prices.

How does filecoin operate ?
Filecoin has a network of storage spaces. The individuals or organizations (clients) who provide storage are called as storage miners. You pay storage miners in filecoin(native cryptocurrency of filecoin network) for certain size and period of time. You can get an idea from picture in above section. You are aware that the price of cryptocurrency is volatile but even taking that into account, you can find that storing in filecoin is way cheaper that the centralized storage.
You may wonder how can we trust storage miners. Well, Filecoin has various methods which ensures that storage miners don’t default. Firstly, a miner will stake some amount of filecoin as collateral to provide storage. So, If he fails to provide or stops in the mid-way of time period, he will face penalty. Next, filecoin has two proofs: Proof of Replication (PoRep) and Proof of Spacetime (PoSt).
Proof of Replication(PoRep)
Here there are two persons: A prover and a Verifier. A prover here is the person who stores the data(storage miner). Now, the prover needs to replicate the data in n copies and need to prove the verifier that he has correctly replicated the data.
Proof of Replication is a combination of two proofs: Proof of Storage and Proof of Retrievability. Proof of Storage means a miner should provide a proof that he is using the required amount of space to store the data.
In Proof of Retrievability, a verifier retrieves the file from the prover to make sure that he has it.
To know about the technical part of PoRep, you can click here
Replica and duplicate are slightly different. A duplicate is an exact copy of the original whereas replica is a unique copy of the original. That means we cant differentiate the duplicates but we can differentiate between replicas. We can identify each replica. This can be done by mathematical operations(like encoding CID’s)
Proof of Spacetime(PoSt)
PoRep is done only once at the time of storing the data. Afterwards, PoSt make sures that the storage miner is maintaining the data in his storage. PoSt selects a subset of data and checks whether they are present in the storage of miner. This process is done on intervals of time until the end of period.
To know more about PoSt, click here
How Filecoin has cheaper rates than its competitors?
You may wonder how filecoin has cheaper rates. That’s because its a hyper-competitive market. When a Client wants to store data, he searches in the marketplace where storage miners list their prices for storing the data. Example Miner A can give 0.02 FIL for 500 TB, Miner B can give 0.01 FIL for same 500TB etc. Now the client chooses the most affordable and best option for him. When he selects a miner, a deal is done and after that client sends data to the storage miner.
A storage miner will get two rewards: Storage fees and Block Rewards. Storage fees is the money paid by the client. Storage miner can also get block rewards. First, filecoin has a blockchain. All the deals between clients and storage miners are written on the blockchain. Also blockchain is used to send FIL from one peer to another peer. Filecoin selects a group of storage miners to mine blocks and get rewards accordingly.
Before getting to know the filecoin blockchain, we need to address another thing. How to retrieve data from filecoin network? Until now we talked about the process of storing data which is termed as “Storage Market”. Now we will be discussing the process of retrieving data which is termed as “Retrieving market”.
Retrieving Market
There are two types of nodes in filecoin: Storage nodes and Retrieval nodes. Storage nodes stores the data whereas Retrieval nodes fetch data from the stored nodes to clients.
Person operating a storage node is referred as Storage miner whereas person operating a Retrieval node is referred as a “Provider”. Similar to the case with storage miners, clients need to make deals with providers to retrieve data and these deals will be stored on blockchain.
By reading this, you might figure it out that it’s just a CDN(Content Delivery Network). Filecoin Retrieval Market acts as a CDN for Web3. Internet is fast because of CDN. CDN is a network of PoP(points of Presence, which are strategically located data centers). Whenever you request for a webpage, it first fetches from nearby PoP and if is not there, the webpage is fetched to the PoP and then send to the requested individual, so other persons who request the same webpage will fetch from PoP. CDN is like the cache of Internet.
So, retrieval market is network of people or organizations who act as a CDN for the filecoin network. Storage miners store the data and users all around the world can fetch the stored data with the help of providers. Both the actions requires payment in FIL and it will be paid by the Client.
Now, there are big centralized CDN organizations like Azure CDN, AWS CloudFront, Akamai CDN etc. These CDNs work very well and make the web fast, but there is one problem. These organizations are centralized so that they decide the places for the establishment of datacenters. As a result, there are few countries where CDN is not available as these organizations thinks its not profitable. This can be eliminated by decentralized CDN(dCDN).
That’s it for Filecoin. Upto now, I hope you got a clear idea on Filecoin. Now lets explore the real-world scenarios where it will be helpful. I will be selecting the Solana ecosystem as it one of the fastest growing blockchain and has a lot of Dapps.
3. Filecoin use-cases in Solana
There are many projects in filecoin ecosystem which are useful for Solana builders. I will be listing some of them
NFT STORAGE
We all know that NFT is talk of the town. NFT is a digital asset which can either be a jpeg, music file or a video. All these digital assets should be stored somewhere. One such platform to store these NFT’s is NFT STORAGE. nft.storage is a free decentralized storage built on IPFS and Filecoin.
If you have good knowledge on NFT’s, you might know what a rug pull is. But do you know how the term Rug Pull coined? Well in 2021, a hacker found the whereabouts of the file of NFT and changed it to an image of a Rug. These type of actions can lead to lose of millions.
These type of issues can be eliminated by using IPFS as it uses CID’s which are unique to its content. So, you can rest assure that nft.storage is safe and secure.
A lot of NFT marketplaces use nft.storage to store the digital asset data. MAGIC EDEN is the leading NFT Marketplace on Solana which uses nft.storage
If you want to know whether your NFT is on IPFS, you can check on solscan.io

Lets check an NFT in Okay Bears collection.

I searched for this NFT. Click on this and then go to metadata section and click on View URI Metadata present on middle-right of page.

As you can see, its using ipfs.nftstorage to store the image.
So using IPFS and Filecoin is best for storing NFT’s. There are still some NFT marketplace who use centralized storage, this should be converted to IPFS.
OrbitDB

It is a database built on Filecoin which can be used by Node.js applications. The most important thing to know about OrbitDB is that it is a peer-to-peer database. Let me explain you with an example below.
Suppose you have an application which is similar to twitter. Using OrbitDB, you can create a separate database for each individual(peer) to store his/her tweets. Suppose another user follows you, then he gets your tweets in his feed. This is done as OrbitDB replicates your tweets present in the database onto the other user’s feed. This is referred as peer-to-peer database.
Databases in OrbitDB can be synced automatically among peers, it is a eventually consistent database as it uses IPFS. This database can be a good choice for Solana developers to build their dapps.
Myel
In Filecoin section, we have discussed about CDN. Myel is a CDN powered by Filecoin, IPFS, IPLD and Libp2p which is suitable for Web3 applications.
If you need to make you application reach out at a global scale, then you must use CDN. Myel is a decentralized CDN which is resilient, scalable and easy to use.

Myel is a network of peers around the global who hosts your data. Check the above image. I am currently connected to 9 peers located in different locations. I can select peers based on location and upload a file. This file will be hosted on the selected peers from which people near those peers can fetch my file faster.
Pinata

Pinata is a Cloud based SAAS product which makes file storage easy for everyone. It is famously used to manage NFT Media. Built on IPFS, here you can be assured that pinata nodes will always stay online so you can retrieve your data anytime.
There is one major advantage using Pinata. IPFS is a public network meaning all files are public and anybody can access them. But, in Pinata you can make your file private. Pinata has a mechanism through which it can hide your content from IPFS network. Check the official website for more information. Link will be available in Reference section.
REFERENCES
IPFS
https://www.reddit.com/r/ipfs/comments/biflov/the_myths_of_ipfs/
https://stackoverflow.com/questions/47450007/where-does-ipfs-store-all-the-data (IMPORTANT)
https://docs.ipfs.io/
FILECOIN
https://filecoin.io/
https://docs.filecoin.io/
https://spec.filecoin.io/
https://web3.storage/
https://nftschool.dev/
Filecoin use cases in Solana
https://nft.storage/
https://orbitdb.org/
https://www.pinata.cloud/
https://www.myel.network/
Hey there! Such a nice piece, enjoyed it! With whom we can discuss some partnership/collabs opportunities, btw?